MySQL 8.4 发行说明
本节讨论 NDB 集群如何划分和复制数据以进行存储。
接下来的几段将讨论理解本主题的核心概念。
数据节点。 一个 ndbd 或 ndbmtd 进程,它存储一个或多个 分片副本,即分配给节点所属节点组的 分区(本节稍后讨论)的副本。
每个数据节点都应该位于不同的计算机上。虽然也可以在单个计算机上托管多个数据节点进程,但通常不建议这样做。
在指代 ndbd 或 ndbmtd 进程时,术语 “节点” 和 “数据节点” 通常可以互换使用;在本文档中,管理节点(ndb_mgmd 进程)和 SQL 节点(mysqld 进程)将被明确指定。
节点组。 一个节点组由一个或多个节点组成,并存储分区或 分片副本 集(参见下一项)。
NDB 集群中的节点组数量不可直接配置;它是数据节点数量和分片副本数量(NoOfReplicas 配置参数)的函数,如下所示
[# of node groups] = [# of data nodes] / NoOfReplicas因此,如果在 config.ini 文件中将 NoOfReplicas 设置为 1,则具有 4 个数据节点的 NDB 集群将具有 4 个节点组;如果将 NoOfReplicas 设置为 2,则具有 2 个节点组;如果将 NoOfReplicas 设置为 4,则具有 1 个节点组。分片副本将在本节稍后讨论;有关 NoOfReplicas 的更多信息,请参阅 第 25.4.3.6 节,“定义 NDB 集群数据节点”。
注意
NDB 集群中的所有节点组必须具有相同数量的数据节点。
您可以将新的节点组(以及新的数据节点)在线添加到正在运行的 NDB 集群中;有关更多信息,请参阅 第 25.6.7 节,“在线添加 NDB 集群数据节点”。
分区。 这是集群存储的数据的一部分。每个节点负责保留分配给它的任何分区(即至少一个分片副本)的至少一个副本,以供集群使用。
NDB 集群默认使用的分区数量取决于数据节点的数量和数据节点使用的 LDM 线程数量,如下所示
[# of partitions] = [# of data nodes] * [# of LDM threads]使用运行 ndbmtd 的数据节点时,LDM 线程的数量由 MaxNoOfExecutionThreads 的设置控制。使用 ndbd 时,只有一个 LDM 线程,这意味着集群分区数量与参与集群的节点数量相同。在使用 ndbmtd 且 MaxNoOfExecutionThreads 设置为 3 或更小时,情况也是如此。(您应该注意,LDM 线程的数量会随着此参数的值而增加,但不是严格的线性关系,并且对其设置还有其他限制;有关更多信息,请参阅 MaxNoOfExecutionThreads 的描述。)
NDB 和用户定义的分区。 NDB 集群通常会自动对 NDBCLUSTER 表进行分区。但是,也可以对 NDBCLUSTER 表采用用户定义的分区。这受以下限制
在生产环境中,
NDB表仅支持KEY和LINEAR KEY分区方案。可以为任何
NDB表显式定义的最大分区数为8 * [,NDB 集群中的节点组数的确定方式如本节前面所述。运行 ndbd 作为数据节点进程时,设置 LDM 线程数无效(因为LDM 线程数] * [节点组数]ThreadConfig仅适用于 ndbmtd);在这种情况下,为了执行此计算,可以将此值视为等于 1。有关更多信息,请参阅 第 25.5.3 节,“ndbmtd — NDB 集群数据节点守护进程(多线程)”。
有关 NDB 集群和用户定义分区的更多信息,请参阅 第 25.2.7 节,“NDB 集群的已知限制” 和 第 26.6.2 节,“与存储引擎相关的分区限制”。
分片副本。 这是集群分区的一个副本。节点组中的每个节点都存储一个分片副本。有时也称为 分区副本。分片副本的数量等于每个节点组的节点数量。
分片副本完全属于单个节点;一个节点可以(并且通常确实)存储多个分片副本。
下图显示了一个 NDB 集群,该集群有四个运行 ndbd 的数据节点,这些节点被安排在两个节点组中,每个节点组有两个节点;节点 1 和节点 2 属于节点组 0,节点 3 和节点 4 属于节点组 1。
注意
这里只显示数据节点;虽然一个正常工作的 NDB 集群需要一个 ndb_mgmd 进程来进行集群管理,并且至少需要一个 SQL 节点来访问集群存储的数据,但为了清晰起见,这些内容已从图中省略。
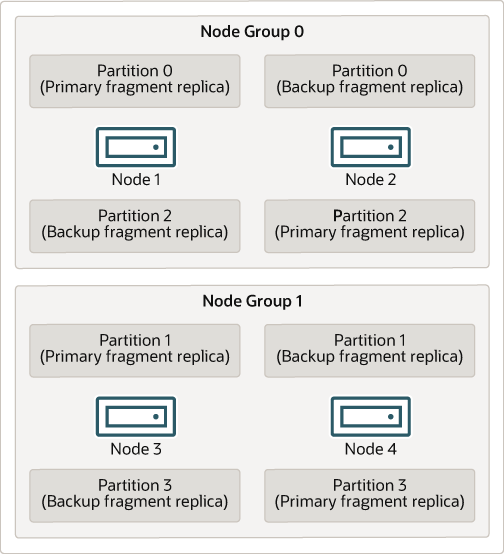
集群存储的数据被分为四个分区,编号为 0、1、2 和 3。每个分区都存储在同一个节点组中(以多个副本的形式)。分区存储在备用节点组上,如下所示
分区 0 存储在节点组 0 上;主分片副本(主副本)存储在节点 1 上,而 备份分片副本(分区的备份副本)存储在节点 2 上。
分区 1 存储在另一个节点组(节点组 1)上;该分区的主分片副本位于节点 3 上,其备份分片副本位于节点 4 上。
分区 2 存储在节点组 0 上。但是,其两个分片副本的放置与分区 0 相反;对于分区 2,主分片副本存储在节点 2 上,备份副本存储在节点 1 上。
分区 3 存储在节点组 1 上,其两个分片副本的放置与分区 1 相反。也就是说,其主分片副本位于节点 4 上,备份副本位于节点 3 上。
这对 NDB 集群的持续运行意味着:只要参与集群的每个节点组至少有一个节点在运行,集群就拥有所有数据的完整副本并保持可用状态。下图对此进行了说明。
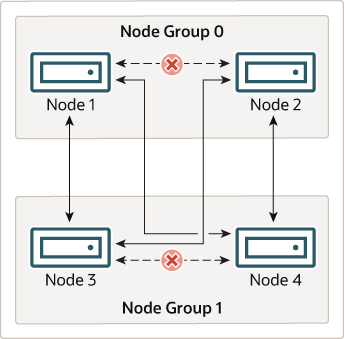
在本例中,集群由两个节点组组成,每个节点组包含两个数据节点。每个数据节点都运行一个 ndbd 实例。只要节点组 0 中至少有一个节点和节点组 1 中至少有一个节点的任意组合就足以保持集群 “活动”。但是,如果来自单个节点组的两个节点都发生故障,则由另一个节点组中剩余两个节点组成的组合将不足以维持集群运行。在这种情况下,集群已丢失整个分区,因此无法再提供对所有 NDB 集群数据的完整集的访问。
单个 NDB 集群实例支持的最大节点组数为 48 个。