MySQL 8.4 发行说明
- 25.7.1 NDB Cluster 复制:缩写和符号
- 25.7.2 NDB Cluster 复制的一般要求
- 25.7.3 NDB Cluster 复制中的已知问题
- 25.7.4 NDB Cluster 复制模式和表
- 25.7.5 为 NDB Cluster 复制做准备
- 25.7.6 启动 NDB Cluster 复制(单复制通道)
- 25.7.7 为 NDB Cluster 复制使用两个复制通道
- 25.7.8 使用 NDB Cluster 复制实现故障转移
- 25.7.9 使用 NDB Cluster 复制进行 NDB Cluster 备份
- 25.7.10 NDB Cluster 复制:双向和循环复制
- 25.7.11 使用多线程应用器进行 NDB Cluster 复制
- 25.7.12 NDB Cluster 复制冲突解决
NDB Cluster 支持 异步复制,通常简称为 “复制”。本节说明如何设置和管理一个配置,其中一组作为 NDB Cluster 运行的计算机复制到第二台计算机或一组计算机。我们假设读者熟悉标准 MySQL 复制,如本手册其他地方所述。(见 第 19 章,复制)。
注意
NDB Cluster 不支持使用 GTID 的复制;NDB 存储引擎也不支持半同步复制和组复制。
普通(非集群)复制涉及一个源服务器和一个副本服务器,源服务器之所以这样命名,是因为要复制的操作和数据起源于它,而副本服务器是这些操作和数据的接收方。在 NDB Cluster 中,复制在概念上非常相似,但在实践中可能更复杂,因为它可以扩展到涵盖许多不同的配置,包括在两个完整集群之间复制。尽管 NDB Cluster 本身依赖于 NDB 存储引擎来实现集群功能,但并非必须使用 NDB 作为副本的复制表的存储引擎(见 从 NDB 到其他存储引擎的复制)。但是,为了获得最大的可用性,可以(也是最优的)从一个 NDB Cluster 复制到另一个 NDB Cluster,这就是我们讨论的场景,如下图所示
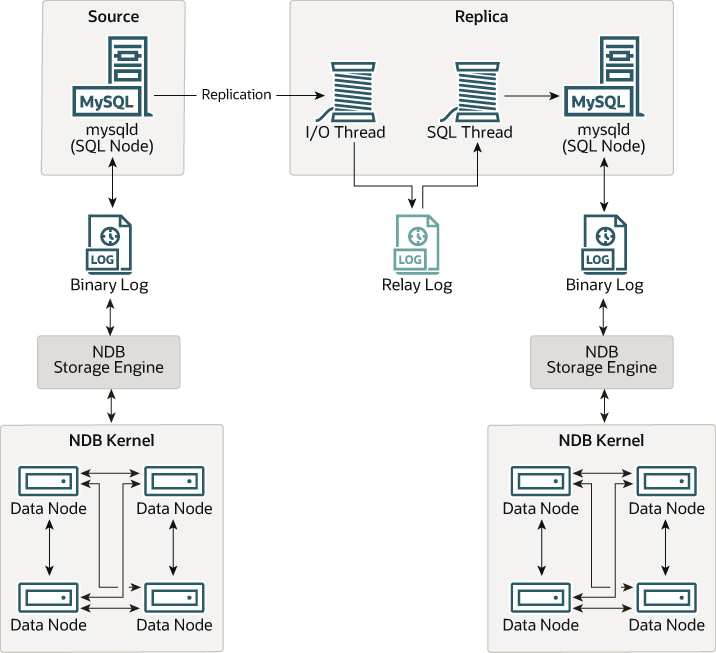
在这种情况下,复制过程是从源集群中记录和保存到副本集群的连续状态。此过程由一个称为 NDB 二进制日志注入线程的特殊线程完成,该线程在每个 MySQL 服务器上运行并生成二进制日志(binlog)。该线程确保生成二进制日志的集群中的所有更改(而不仅仅是通过 MySQL Server 执行的更改)都以正确的序列化顺序插入二进制日志。我们将 MySQL 源服务器和副本服务器称为复制服务器或复制节点,并将它们之间的通信数据流或线路称为 复制通道。
有关使用 NDB Cluster 和 NDB Cluster 复制执行时间点恢复的信息,请参阅 第 25.7.9.2 节,“时间点恢复使用 NDB Cluster 复制”。
NDB API 副本状态变量。 NDB API 计数器可以提供副本集群上增强的监控功能。这些计数器在 NDB 统计信息 _replica 状态变量中实现,如 SHOW STATUS 的输出中或在针对 Performance Schema session_status 或 global_status 表的查询结果中可见,这些查询结果来自连接到充当 NDB Cluster 复制中副本的 MySQL Server 的 mysql 客户端会话。通过比较影响复制的 NDB 表的语句执行前后这些状态变量的值,您可以观察到副本在 NDB API 级别所采取的相应操作,这在监控或故障排除 NDB Cluster 复制时非常有用。 第 25.6.16 节,“NDB API 统计计数器和变量” 提供了更多信息。
从 NDB 到非 NDB 表的复制。 可以将 NDB 表从充当复制源的 NDB Cluster 复制到使用其他 MySQL 存储引擎(如 InnoDB 或 MyISAM)的副本 mysqld 上的表。这受到一些条件的限制;请参阅 从 NDB 到其他存储引擎的复制 和 从 NDB 到非事务性存储引擎的复制,以获取更多信息。