MySQL 9.0 版本说明
可以使用 NDB Cluster 在两个集群之间进行双向复制,以及在任意数量的集群之间进行循环复制。
循环复制示例。 在接下来的几段中,我们将考虑一个涉及三个 NDB Cluster(编号为 1、2 和 3)的复制设置示例,其中 Cluster 1 充当 Cluster 2 的复制源,Cluster 2 充当 Cluster 3 的源,Cluster 3 充当 Cluster 1 的源。每个集群有两个 SQL 节点,其中 SQL 节点 A 和 B 属于 Cluster 1,SQL 节点 C 和 D 属于 Cluster 2,SQL 节点 E 和 F 属于 Cluster 3。
只要满足以下条件,就可以使用这些集群支持循环复制。
所有源和副本上的 SQL 节点相同。
所有充当源和副本的 SQL 节点都使用系统变量
log_replica_updates启用启动。
以下图表显示了这种类型的循环复制设置。
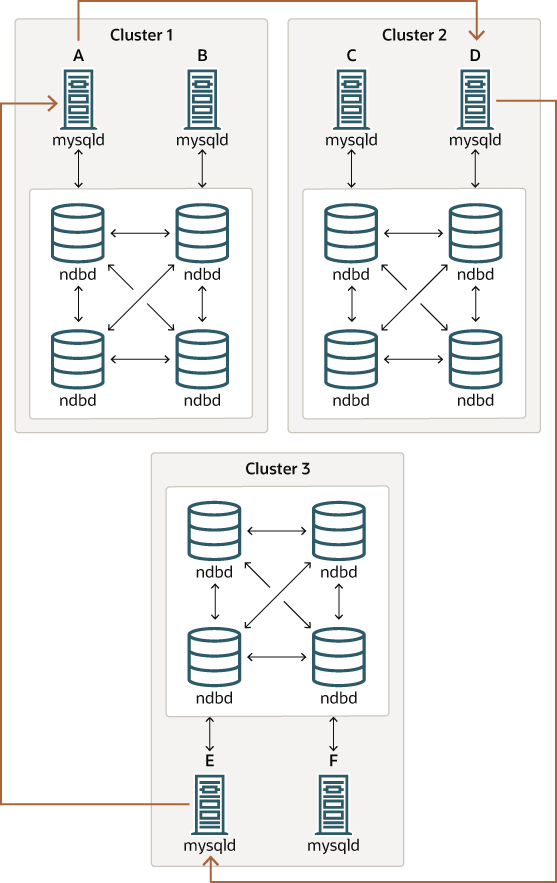
在这种情况下,Cluster 1 中的 SQL 节点 A 复制到 Cluster 2 中的 SQL 节点 C;SQL 节点 C 复制到 Cluster 3 中的 SQL 节点 E;SQL 节点 E 复制到 SQL 节点 A。换句话说,复制线(在图表中由弯曲箭头表示)直接连接所有用作复制源和副本的 SQL 节点。
还可以以并非所有源 SQL 节点也是副本的方式设置循环复制,如下所示。
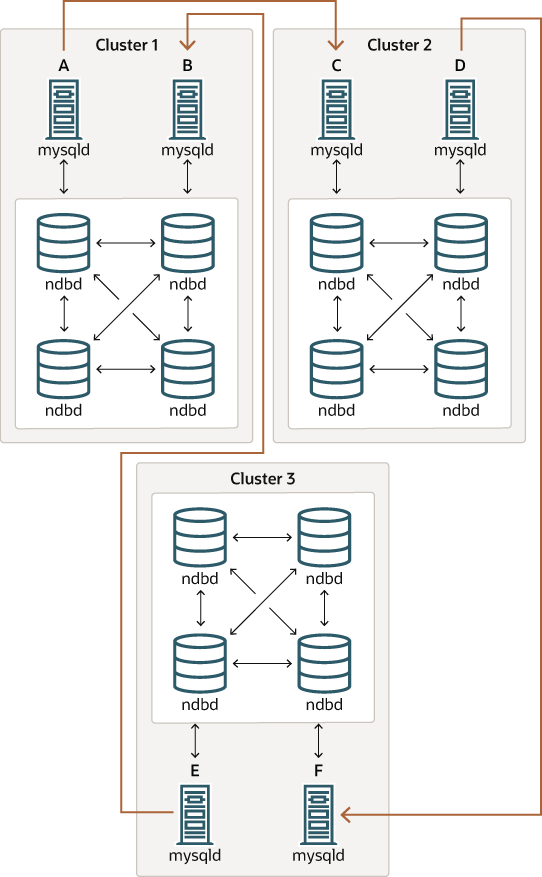
在这种情况下,每个集群中的不同 SQL 节点用作复制源和副本。必须不使用系统变量 log_replica_updates 启用启动任何 SQL 节点。这种类型的 NDB Cluster 循环复制方案,其中复制线(在图表中由弯曲箭头表示)是不连续的,应该是可能的,但应该注意,它尚未经过彻底测试,因此仍然应被视为实验性的。
使用 NDB 本机备份和恢复来初始化副本集群。 在设置循环复制时,可以使用管理客户端 START BACKUP 命令在一个 NDB Cluster 上创建备份,然后使用 ndb_restore 将此备份应用到另一个 NDB Cluster 上。这不会自动在充当副本的第二个 NDB Cluster 的 SQL 节点上创建二进制日志;为了创建二进制日志,您必须在该 SQL 节点上发出 SHOW TABLES 语句;这应该在运行 START REPLICA 之前完成。这是一个已知问题。
多源故障转移示例。 在本节中,我们将讨论在具有三个 NDB Cluster(服务器 ID 为 1、2 和 3)的多源 NDB Cluster 复制设置中进行故障转移。在这种情况下,Cluster 1 复制到 Cluster 2 和 Cluster 3;Cluster 2 也复制到 Cluster 3。这种关系如下所示。
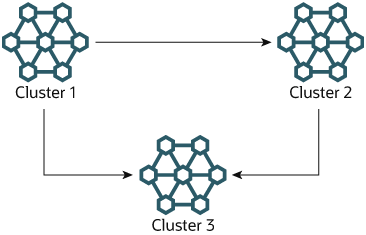
换句话说,数据通过 2 个不同的路由从 Cluster 1 复制到 Cluster 3:直接复制和通过 Cluster 2 复制。
并非所有参与多源复制的 MySQL 服务器都必须充当源和副本,并且给定的 NDB Cluster 可能会为不同的复制通道使用不同的 SQL 节点。这种情况如下所示。
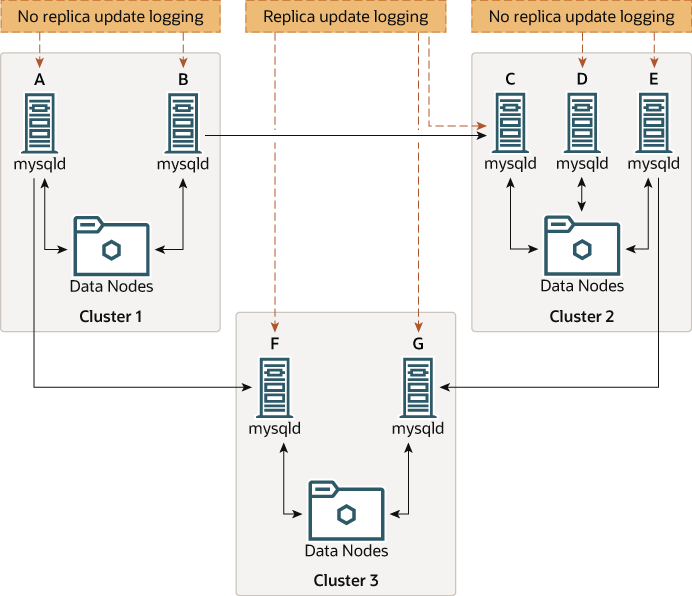
充当副本的 MySQL 服务器必须使用系统变量 log_replica_updates 启用运行。哪些 mysqld 进程需要此选项也在前面的图表中显示。
注意
使用 log_replica_updates 系统变量对未作为副本运行的服务器没有影响。
当复制集群之一出现故障时,就会出现故障转移的必要性。在本示例中,我们将考虑 Cluster 1 无法使用的情况,因此 Cluster 3 失去了来自 Cluster 1 的 2 个更新源。由于 NDB Cluster 之间的复制是异步的,因此无法保证来自 Cluster 1 的 Cluster 3 更新比通过 Cluster 2 收到的更新更近期。您可以通过确保 Cluster 3 在来自 Cluster 1 的更新方面赶上 Cluster 2 来解决这个问题。就 MySQL 服务器而言,这意味着您需要将来自 MySQL 服务器 C 到服务器 F 的任何未完成更新复制过去。
在服务器 C 上,执行以下查询。
mysqlC> SELECT @latest:=MAX(epoch)
-> FROM mysql.ndb_apply_status
-> WHERE server_id=1;
mysqlC> SELECT
-> @file:=SUBSTRING_INDEX(File, '/', -1),
-> @pos:=Position
-> FROM mysql.ndb_binlog_index
-> WHERE orig_epoch >= @latest
-> AND orig_server_id = 1
-> ORDER BY epoch ASC LIMIT 1;注意
您可以通过在 ndb_binlog_index 表中添加适当的索引来提高此查询的性能,从而可能显著加快故障转移时间。有关更多信息,请参见 第 25.7.4 节,“NDB Cluster 复制模式和表”。
将 @file 和 @pos 的值从服务器 C 手动复制到服务器 F(或让您的应用程序执行等效操作)。然后,在服务器 F 上,执行以下 CHANGE REPLICATION SOURCE TO 语句
mysqlF> CHANGE REPLICATION SOURCE TO
-> SOURCE_HOST = 'serverC'
-> SOURCE_LOG_FILE='@file',
-> SOURCE_LOG_POS=@pos;完成此操作后,您可以在 MySQL 服务器 F 上发出 START REPLICA 语句;这会导致来自服务器 B 的任何缺少的更新被复制到服务器 F。
The CHANGE REPLICATION SOURCE TO 语句还支持 IGNORE_SERVER_IDS 选项,该选项接受以逗号分隔的服务器 ID 列表,并导致来自相应服务器的事件被忽略。有关此语句的更多信息,以及 第 15.7.7.34 节,“SHOW REPLICA STATUS 语句”,请参见该语句的文档。有关此选项如何与 ndb_log_apply_status 变量交互的信息,请参见 第 25.7.8 节,“使用 NDB Cluster 复制实现故障转移”。