MySQL 9.0 发行说明
本节讨论使用 NDB 集群进行复制时的已知问题。
源集群和副本集群之间失去连接。 源集群 SQL 节点和副本集群 SQL 节点之间,或者源 SQL 节点和源集群的数据节点之间都可能发生连接丢失。在后一种情况下,这不仅可能由于物理连接丢失(例如,网线断裂)而发生,还可能由于数据节点事件缓冲区溢出而发生;如果 SQL 节点响应太慢,它可能会被集群丢弃(这可以通过调整 MaxBufferedEpochs 和 TimeBetweenEpochs 配置参数在一定程度上控制)。如果发生这种情况,完全有可能将新数据插入到源集群中,而不会记录在源 SQL 节点的二进制日志中。因此,为了保证高可用性,维护一个备份复制通道、监控主通道并在必要时故障转移到辅助复制通道以保持副本集群与源集群同步是极其重要的。NDB 集群本身并不能执行此类监控;为此,需要一个外部应用程序。
源 SQL 节点在连接或重新连接到源集群时会发出 “间隙” 事件。(间隙事件是一种 “事件事件”, 表示发生的事件会影响数据库的内容,但不能轻易地表示为一组更改。事件的例子包括服务器故障、数据库重新同步、一些软件更新和一些硬件更改。)当副本在复制日志中遇到间隙时,它会停止并显示一条错误消息。此消息可在 SHOW REPLICA STATUS 的输出中找到,它表示 SQL 线程已因复制流中注册的事件而停止,并且需要手动干预。有关在此类情况下该怎么办的更多信息,请参见 第 25.7.8 节,“使用 NDB 集群复制实现故障转移”。
重要
由于 NDB 集群本身并非为监控复制状态或提供故障转移而设计,因此,如果高可用性是副本服务器或集群的要求,则必须设置多条复制线路,监控主复制线路上的源 mysqld,并在必要时准备好故障转移到辅助线路。这必须手动完成,或者可能通过第三方应用程序完成。有关实现此类设置的信息,请参见 第 25.7.7 节,“为 NDB 集群复制使用两个复制通道” 和 第 25.7.8 节,“使用 NDB 集群复制实现故障转移”。
如果要从独立的 MySQL 服务器复制到 NDB 集群,一个通道通常就足够了。
循环复制。 NDB 集群复制支持循环复制,如下例所示。复制设置涉及三个编号为 1、2 和 3 的 NDB 集群,其中集群 1 充当集群 2 的复制源,集群 2 充当集群 3 的源,集群 3 充当集群 1 的源,从而完成循环。每个 NDB 集群有两个 SQL 节点,SQL 节点 A 和 B 属于集群 1,SQL 节点 C 和 D 属于集群 2,SQL 节点 E 和 F 属于集群 3。
只要满足以下条件,就支持使用这些集群进行循环复制
所有源集群和副本集群上的 SQL 节点都相同。
所有充当源和副本的 SQL 节点都在启用系统变量
log_replica_updates的情况下启动。
这种类型的循环复制设置如下图所示
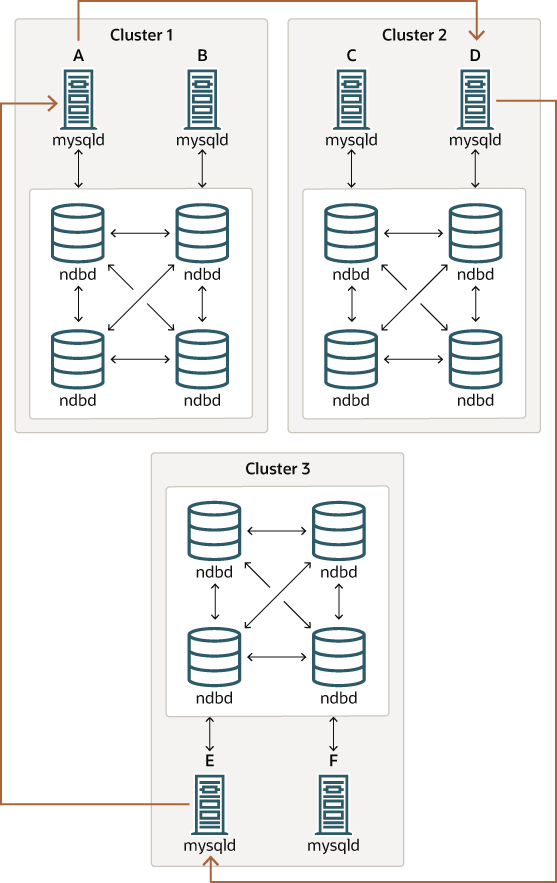
在这种情况下,集群 1 中的 SQL 节点 A 复制到集群 2 中的 SQL 节点 C;SQL 节点 C 复制到集群 3 中的 SQL 节点 E;SQL 节点 E 复制到 SQL 节点 A。换句话说,复制线(图中用弯曲箭头表示)直接连接用作源和副本的所有 SQL 节点。
还应该可以设置循环复制,其中并非所有源 SQL 节点也都是副本,如下所示
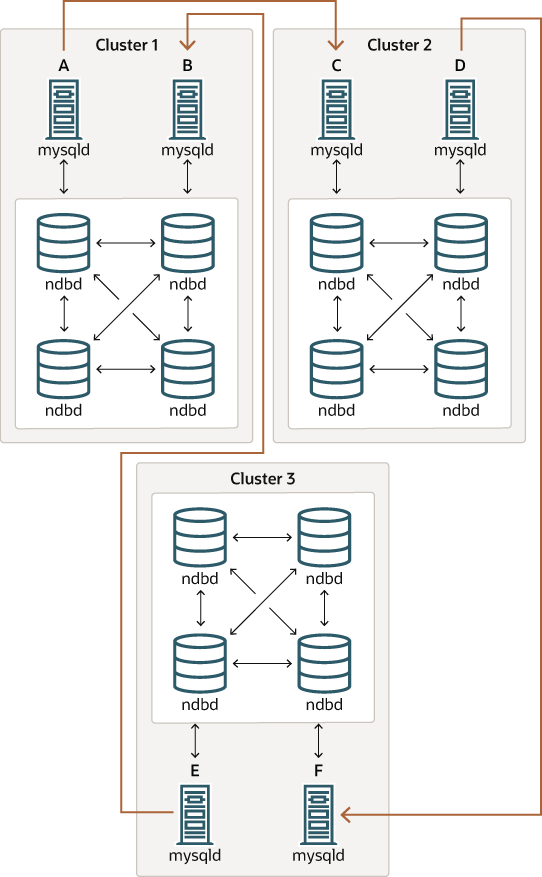
在这种情况下,每个集群中的不同 SQL 节点用作源和副本。但是,不得 在启用 log_replica_updates 系统变量的情况下启动任何 SQL 节点。这种类型的 NDB 集群循环复制方案(图中用弯曲箭头表示的复制线是不连续的)应该是可行的,但应该注意的是,它尚未经过全面测试,因此必须仍然被视为实验性的。
注意
NDB 存储引擎使用 幂等执行模式,这会抑制重复键和其他错误,否则会破坏 NDB 集群的循环复制。这等效于将系统变量 replica_exec_mode 的全局值设置为 IDEMPOTENT,尽管这在 NDB 集群复制中不是必需的,因为 NDB 集群会自动设置此变量并忽略任何显式设置它的尝试。
NDB 集群复制和主键。 如果节点发生故障,复制没有主键的 NDB 表时仍然可能出现错误,因为在这种情况下可能会插入重复的行。因此,强烈建议所有要复制的 NDB 表都具有显式主键。
NDB 集群复制和唯一键。 在旧版本的 NDB 集群中,更新 NDB 表的唯一键列的值的操作在复制时可能会导致重复键错误。通过将唯一键检查推迟到所有表行更新都执行完毕之后,可以解决 NDB 表之间的复制问题。
目前只有 NDB 支持以这种方式推迟约束。因此,从 NDB 复制到其他存储引擎(如 InnoDB 或 MyISAM)时更新唯一键仍然不受支持。
可以使用 NDB 表(如 t)来说明在没有延迟检查唯一键更新的情况下进行复制时遇到的问题,该表是在源上创建并填充的(并传输到不支持延迟唯一键更新的副本),如下所示
CREATE TABLE t (
p INT PRIMARY KEY,
c INT,
UNIQUE KEY u (c)
) ENGINE NDB;
INSERT INTO t
VALUES (1,1), (2,2), (3,3), (4,4), (5,5);以下对 t 的 UPDATE 语句在源上成功,因为受影响的行按照 ORDER BY 选项确定的顺序处理,并在整个表上执行
UPDATE t SET c = c - 1 ORDER BY p;相同的语句在副本上失败并显示重复键错误或其他约束冲突,因为行更新的排序是针对一个分区一次执行的,而不是针对整个表执行的。
注意
每个 NDB 表在创建时都会按键隐式分区。有关更多信息,请参见 第 26.2.5 节,“KEY 分区”。
不支持 GTID。 使用全局事务 ID 进行复制与 NDB 存储引擎不兼容,因此不受支持。启用 GTID 可能会导致 NDB 集群复制失败。
使用 --initial 重新启动。 使用 --initial 选项重新启动集群会导致 GCI 和时期号的序列从 0 开始。(这通常适用于 NDB 集群,而不限于涉及集群的复制场景。)在这种情况下,应重新启动参与复制的 MySQL 服务器。之后,应使用 RESET BINARY LOGS AND GTIDS 和 RESET REPLICA 语句分别清除无效的 ndb_binlog_index 和 ndb_apply_status 表。
从 NDB 复制到其他存储引擎。 可以将源上的 NDB 表复制到副本上使用不同存储引擎的表,同时考虑到此处列出的限制
不支持多源和循环复制(源和副本上的表都必须使用
NDB存储引擎才能正常工作)。对副本上的表使用不执行二进制日志记录的存储引擎需要特殊处理。
对副本上的表使用非事务性存储引擎也需要特殊处理。
必须使用
--ndb-log-update-as-write=0或--ndb-log-update-as-write=OFF启动源 mysqld。
接下来的几段将提供有关刚刚描述的每个问题的更多信息。
将 NDB 复制到其他存储引擎时不支持多个源。 当从 NDB 复制到不同的存储引擎时,两个数据库之间的关系必须是一对一的。这意味着 NDB Cluster 和其他存储引擎之间不支持双向或循环复制。
此外,在 NDB 和不同存储引擎之间进行复制时,无法配置多个复制通道。(一个 NDB Cluster 数据库可以同时复制到多个 NDB Cluster 数据库。)如果源使用 NDB 表,则仍然可以让多个 MySQL 服务器维护所有更改的二进制日志,但是要使副本更改源(故障转移),则必须在副本上显式定义新的源-副本关系。
将 NDB 表复制到不执行二进制日志记录的存储引擎。 如果您尝试从 NDB Cluster 复制到使用不处理其自身二进制日志记录的存储引擎的副本,则复制过程将中止,并显示错误 无法进行二进制日志记录... 由于涉及多个引擎并且至少一个引擎正在进行自我日志记录,因此无法原子地写入语句(错误 1595)。可以通过以下方法之一解决此问题:
关闭副本上的二进制日志记录。 这可以通过设置
sql_log_bin = 0来实现。更改 mysql.ndb_apply_status 表使用的存储引擎。 使此表使用不处理其自身二进制日志记录的引擎也可以消除冲突。这可以通过在副本上发出如下语句来完成:
ALTER TABLE mysql.ndb_apply_status ENGINE=MyISAM。在副本上使用NDB以外的存储引擎时,这样做是安全的,因为您无需担心保持多个副本同步。过滤掉副本上对 mysql.ndb_apply_status 表的更改。 这可以通过使用
--replicate-ignore-table=mysql.ndb_apply_status启动副本来完成。如果您需要复制操作忽略其他表,则可能希望改用适当的--replicate-wild-ignore-table选项。
重要
当从一个 NDB Cluster 复制到另一个 NDB Cluster 时,您不应禁用 mysql.ndb_apply_status 的复制或二进制日志记录,也不应更改用于此表的存储引擎。有关详细信息,请参见NDB Cluster 之间的复制和二进制日志过滤规则。
从 NDB 复制到非事务性存储引擎。 当从 NDB 复制到非事务性存储引擎(例如 MyISAM)时,在复制 INSERT ... ON DUPLICATE KEY UPDATE 语句时,您可能会遇到不必要的重复键错误。您可以使用 --ndb-log-update-as-write=0 来抑制这些错误,该选项强制将更新记录为写入,而不是更新。
NDB 复制和文件系统加密 (TDE)。 加密文件系统的使用对 NDB 复制没有任何影响。支持以下所有场景:
将具有加密文件系统的 NDB Cluster 复制到文件系统未加密的 NDB Cluster。
将文件系统未加密的 NDB Cluster 复制到文件系统已加密的 NDB Cluster。
将文件系统已加密的 NDB Cluster 复制到使用未加密的
InnoDB表的独立 MySQL 服务器。将具有未加密文件系统的 NDB Cluster 复制到使用文件系统加密的
InnoDB表的独立 MySQL 服务器。
NDB Cluster 之间的复制和二进制日志过滤规则。 如果您正在使用任何 --replicate-do-*、--replicate-ignore-*、--binlog-do-db 或 --binlog-ignore-db 选项来过滤要复制的数据库或表,则必须注意不要阻止 mysql.ndb_apply_status 的复制或二进制日志记录,这对于 NDB Cluster 之间的复制正常运行是必需的。特别是,您必须牢记以下几点:
使用
--replicate-do-db=(并且没有其他db_name--replicate-do-*或--replicate-ignore-*选项)意味着仅复制数据库db_name中的表。在这种情况下,您还应该使用--replicate-do-db=mysql、--binlog-do-db=mysql或--replicate-do-table=mysql.ndb_apply_status来确保在副本上填充mysql.ndb_apply_status。使用
--binlog-do-db=(并且没有其他db_name--binlog-do-db选项)意味着仅将对数据库db_name中表的更改写入二进制日志。在这种情况下,您还应该使用--replicate-do-db=mysql、--binlog-do-db=mysql或--replicate-do-table=mysql.ndb_apply_status来确保在副本上填充mysql.ndb_apply_status。使用
--replicate-ignore-db=mysql意味着不复制mysql数据库中的任何表。在这种情况下,您还应该使用--replicate-do-table=mysql.ndb_apply_status来确保复制mysql.ndb_apply_status。使用
--binlog-ignore-db=mysql意味着不会将对mysql数据库中表的任何更改写入二进制日志。在这种情况下,您还应该使用--replicate-do-table=mysql.ndb_apply_status来确保复制mysql.ndb_apply_status。
您还应该记住,每个复制规则都需要以下内容:
它自己的
--replicate-do-*或--replicate-ignore-*选项,并且不能在单个复制过滤选项中表达多个规则。有关这些规则的信息,请参见第 19.1.6 节“复制和二进制日志记录选项和变量”。它自己的
--binlog-do-db或--binlog-ignore-db选项,并且不能在单个二进制日志过滤选项中表达多个规则。有关这些规则的信息,请参见第 7.4.4 节“二进制日志”。
如果您要将 NDB Cluster 复制到使用 NDB 以外的存储引擎的副本,则前面给出的注意事项可能不适用,如本节其他地方所述。
NDB Cluster 复制和 IPv6。 所有类型的 NDB Cluster 节点在 NDB 9.0 中都支持 IPv6;这包括管理节点、数据节点和 API 或 SQL 节点。
注意
在 NDB 9.0 中,如果您不打算对任何 NDB Cluster 节点使用 IPv6 地址,则可以在 Linux 内核中禁用 IPv6 支持。
属性提升和降级。 NDB Cluster 复制包括对属性提升和降级的支持。后者的实现区分了有损和无损类型转换,并且可以通过设置系统变量 replica_type_conversions 的全局值来控制它们在副本上的使用。
有关 NDB Cluster 中属性提升和降级的更多信息,请参见基于行的复制:属性提升和降级。
与 InnoDB 或 MyISAM 不同,NDB 不会将对虚拟列的更改写入二进制日志;但是,这对 NDB Cluster 复制或 NDB 和其他存储引擎之间的复制没有不利影响。将记录对存储的生成列的更改。