MySQL NDB Cluster 8.1 手册
MySQL NDB Cluster 8.0 手册
NDB Cluster 内部手册
一个 NDB Cluster 被定义为一个或多个 MySQL 服务器,它们提供对 NDBCLUSTER 存储引擎的访问,即访问一组 NDB Cluster 数据节点(ndbd 进程)。从 Java 到 NDBCLUSTER 的三种主要访问路径如下:
JDBC 和 mysqld. JDBC 通过向 MySQL 服务器发送 SQL 语句并返回结果集来工作。使用 JDBC 时,您必须编写 SQL、管理连接,并将您要在程序中用作对象的任何数据从结果集中复制出来。最常与 MySQL 服务器一起使用的 JDBC 实现是 MySQL Connector/J.
Java 持久性 API (JPA) 和 JDBC. JPA 使用 JDBC 连接到 MySQL 服务器。与 JDBC 不同,JPA 提供了数据库中数据的对象视图。
ClusterJ. ClusterJ 使用一个 JNI 桥接连接到 NDB API,以直接访问
NDBCLUSTER。它采用了一种数据访问方式,该方式基于域对象模型,在许多方面类似于 JPA 所采用的方式。ClusterJ 不依赖于 MySQL 服务器进行数据访问。
这些路径在以下 API 堆栈图中显示
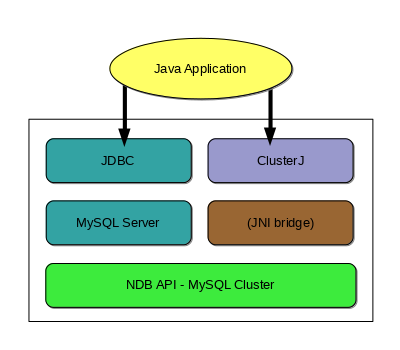
JDBC 和 mysqld. Connector/J 通过 MySQL JDBC 驱动程序提供标准访问。使用 Connector/J,JDBC 应用程序可以编写为与充当 NDB Cluster SQL 节点的 MySQL 服务器一起工作,其方式与其他 Connector/J 应用程序与任何其他 MySQL 服务器实例一起工作的方式基本相同。
有关更多信息,请参见 第 4.2.3 节,“使用 Connector/J 与 NDB Cluster”.
ClusterJ. ClusterJ 是 NDBCLUSTER(或 NDB)的本机 Java 连接器,NDBCLUSTER 是 NDB Cluster 的存储引擎,其风格类似于 Hibernate、JPA 和 JDO。与其他持久性框架一样,ClusterJ 使用 数据映射器模式,其中数据表示为域对象,与业务逻辑分离,将 Java 类映射到存储在 NDBCLUSTER 存储引擎中的数据库表。
注意
在 MySQL 文档和其他地方,NDBCLUSTER 存储引擎通常简称为 NDB。术语 NDB 和 NDBCLUSTER 是同义词,您可以在 CREATE TABLE 语句中使用 ENGINE=NDB 或 ENGINE=NDBCLUSTER 来创建集群表。
ClusterJ 不需要连接到 mysqld 进程,它通过包含在动态库 libnbdclient 中的 JNI 桥接直接访问 NDBCLUSTER。但是,与 JDBC 不同,ClusterJ 不支持表创建和其他数据定义操作;这些必须通过其他方法执行,例如 JDBC 或 mysql 客户端。此外,ClusterJ 限于对单个表的查询,不支持关系或继承;如果您需要在应用程序中支持这些功能,则应使用其他类型的访问路径。